Intelligent Masking: Deep Q-Learning for Context Encoding in Medical Image Analysis
 Intelligent Masking
Intelligent MaskingAbstract
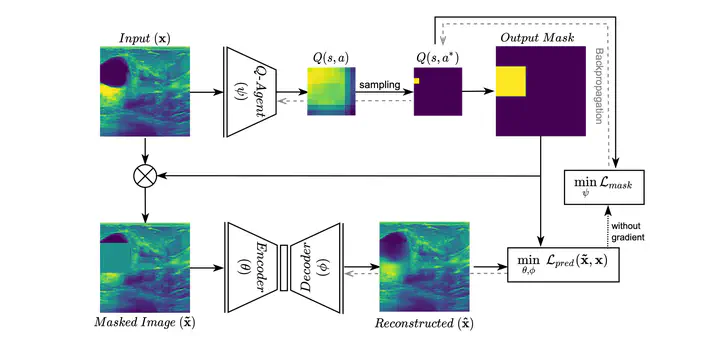
The need for a large amount of labeled data in the supervised setting has led recent studies to utilize self-supervised learning to pre-train deep neural networks using unlabeled data. Many self-supervised training strategies have been investigated especially for medical datasets to leverage the information available in the much fewer unlabeled data. One of the fundamental strategies in image-based self-supervision is context prediction. In this approach, a model is trained to reconstruct the contents of an arbitrary missing region of an image based on its surroundings. However, the existing methods adopt a random and blind masking approach by focusing uniformly on all regions of the images. This approach results in a lot of unnecessary network updates that cause the model to forget the rich extracted features. In this work, we develop a novel self-supervised approach that occludes targeted regions to improve the pre-training procedure. To this end, we propose a reinforcement learning-based agent which learns to intelligently mask input images through deep Q-learning. We show that training the agent against the prediction model can significantly improve the semantic features extracted for downstream classification tasks. We perform our experiments on two public datasets for diagnosing breast cancer in the ultrasound images and detecting lower-grade glioma with MR images. In our experiments, we show that our novel masking strategy advances the learned features according to the performance on the classification task in terms of accuracy, macro F1, and AUROC.
Mojtaba Bahrami
PhD Student in Machine Learning and Computational Biology
My research interests include machine learning, computational biology, and single-cell genomics—with a focus on foundation models, self-supervised learning, and perturbation analysis.